Monday, February 15, 2016
Software Systems engineering; old vs new
Liked this discussion. Making a note : https://news.ycombinator.com/item?id=11099925
Tuesday, January 26, 2016
Reverse Turing Test
Anyone aware of a reverse Turing test ? I.e. how to prove that one is a machine -- please let me know.
Btw, on the topic here is a funny paper i came across: https://www.msu.edu/~pennock5/courses/ALife/Striegel_Failed_Turing_test.pdf
(also follow up on this game: http://www.engadget.com/2015/04/28/spyparty-new-characters-indie-aa/)
Btw, on the topic here is a funny paper i came across: https://www.msu.edu/~pennock5/courses/ALife/Striegel_Failed_Turing_test.pdf
(also follow up on this game: http://www.engadget.com/2015/04/28/spyparty-new-characters-indie-aa/)
Friday, October 30, 2015
Tuesday, August 25, 2015
Tuesday, June 16, 2015
Friday, May 8, 2015
Lock modes
Picking it from Wikipedia (Distributed Lock Manager). Making a note basically:
Lock modes[edit]
A process running within a VMSCluster may obtain a lock on a resource. There are six lock modes that can be granted, and these determine the level of exclusivity of been granted, it is possible to convert the lock to a higher or lower level of lock mode. When all processes have unlocked a resource, the system's information about the resource is destroyed.
- Null (NL). Indicates interest in the resource, but does not prevent other processes from locking it. It has the advantage that the resource and its lock value block are preserved, even when no processes are locking it.
- Concurrent Read (CR). Indicates a desire to read (but not update) the resource. It allows other processes to read or update the resource, but prevents others from having exclusive access to it. This is usually employed on high-level resources, in order that more restrictive locks can be obtained on subordinate resources.
- Concurrent Write (CW). Indicates a desire to read and update the resource. It also allows other processes to read or update the resource, but prevents others from having exclusive access to it. This is also usually employed on high-level resources, in order that more restrictive locks can be obtained on subordinate resources.
- Protected Read (PR). This is the traditional share lock, which indicates a desire to read the resource but prevents other from updating it. Others can however also read the resource.
- Protected Write (PW). This is the traditional update lock, which indicates a desire to read and update the resource and prevents others from updating it. Others with Concurrent Read access can however read the resource.
- Exclusive (EX). This is the traditional exclusive lock which allows read and update access to the resource, and prevents others from having any access to it.
The following truth table shows the compatibility of each lock mode with the others:
| Mode | NL | CR | CW | PR | PW | EX |
|---|---|---|---|---|---|---|
| NL | Yes | Yes | Yes | Yes | Yes | Yes |
| CR | Yes | Yes | Yes | Yes | Yes | No |
| CW | Yes | Yes | Yes | No | No | No |
| PR | Yes | Yes | No | Yes | No | No |
| PW | Yes | Yes | No | No | No | No |
| EX | Yes | No | No | No | No | No |
Thursday, May 7, 2015
Root Certificate, Proxy and HTTPS (and HTTPS for CDN)
Quick note as to how proxies (such as CDN caching machines) can use HTTPS to enact a Man in the Middle.
http://security.stackexchange.com/questions/8145/does-https-prevent-man-in-the-middle-attacks-by-proxy-server
End client lets say trying to talk HTTPS to google.com through a proxy (e.g. a CDN server). In this case, if the proxy sends its own certificate as a "root" certificate either signed by itself, or signed by a trusted third party, and if that certificate is accepted by the client, then when the client tries to contact google.com, client will first look at google.com's certificate, but which in this case would be given by the proxy to the client and which uses proxy's public key for encryption. When the client encrypts using the proxy's public key, the proxy can decrypt and then send it over to google using google's public key (which came through the certificate that was sent by google to the proxy). This way, the proxy can intercept all HTTPS communication.
http://security.stackexchange.com/questions/8145/does-https-prevent-man-in-the-middle-attacks-by-proxy-server
End client lets say trying to talk HTTPS to google.com through a proxy (e.g. a CDN server). In this case, if the proxy sends its own certificate as a "root" certificate either signed by itself, or signed by a trusted third party, and if that certificate is accepted by the client, then when the client tries to contact google.com, client will first look at google.com's certificate, but which in this case would be given by the proxy to the client and which uses proxy's public key for encryption. When the client encrypts using the proxy's public key, the proxy can decrypt and then send it over to google using google's public key (which came through the certificate that was sent by google to the proxy). This way, the proxy can intercept all HTTPS communication.
Monday, April 13, 2015
effective coding habits
http://www.infoq.com/presentations/7-ineffective-coding-habits kind of silly but still pretty useful
Wednesday, April 8, 2015
Thursday, February 19, 2015
Quick Recap of J2EE
As can be seen here, a request for getting a jsp first reaches a web-server (e.g. apache). Apache checks up its virtualhost for the specified URL, identifies the document root, picks up the JSP, and then Apache then hands over the request via module mod_jk to Tomcat, whose job it is to do the following
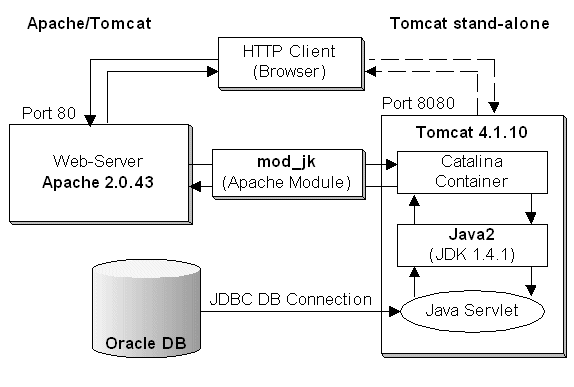
One can even look upon the processing as follows (taken from Wikipedia)

If one is looking at things from the J2EE model, one typically works with a MVC relationship between classes - the relationship works as follows (ill put up a picture on this soon).
Monday, February 16, 2015
Software Engineering
Making a list of some software engineering concepts and principles ive come across.
- Decorator (wrapper where API of object being used is same as exposed)
- Adaptor (wrapper but where API of object being used is different from exposed API)
- Singleton (static object, private constructor)
- Factory (when e.g. one needs to create an Matrix of different types based on the type specified in the constructor e.g.). See this
- Inversion of control e.g. the same example i described above for factory can be better implemented when each Matrix type is implementing an interface (or extending virtual classes) and when the factory class's constructor is created, the concrete object is passed, and then appropriate functions can be called). See this
- Definition of "static" keyword in C++: this keyword has 3 uses. limit scope within translation unit, retain value across function calls, do not be part of object instances
Wednesday, December 3, 2014
Thread Specific heap/tcmalloc
Wanted to write this down somewhere for some time, so doing it now.
As i have touched upon before (and as i understand), user-level threads share the data section of its parent process, as well as the heap of the parent process (note that when a process is "Executed" by the kernel, the kernel allocates an area to execute consisting of the text segment, data segment (memory arena). Because all threads share the heap, the allocation (e.g. done using malloc (in turn using brk or mmap) ) in the heap needs to have a lock, and this is a costly operation. Every time malloc/free is called from any of the threads, a lock has to be taken, then memory allocated/deallocated, while other threads wait on the lock.
With tcmalloc, i would expect that the heap is broken up into parts so that each thread can use only its part of the heap and there is also a centralized heap where the thread will try to grab data from in case of running out of memory on its local heap.
(btw, just while on the topic, making a quick note about Valgrind's issues with tcmalloc: from valgrind man page: "When a shared library is loaded, Valgrind checks for functions in the library that must be replaced or wrapped. For example, Memcheck replaces all malloc related functions (malloc, free, calloc, ...) with its own versions. Such replacements are done by default only in shared libraries whose soname matches a predefined soname pattern (e.g.libc.so* on linux). By default, no replacement is done for a statically linked library or for alternative libraries such as tcmalloc. In some cases, the replacements allow --soname-synonyms to specify one additional synonym pattern, giving flexibility in the replacement".)
As i have touched upon before (and as i understand), user-level threads share the data section of its parent process, as well as the heap of the parent process (note that when a process is "Executed" by the kernel, the kernel allocates an area to execute consisting of the text segment, data segment (memory arena). Because all threads share the heap, the allocation (e.g. done using malloc (in turn using brk or mmap) ) in the heap needs to have a lock, and this is a costly operation. Every time malloc/free is called from any of the threads, a lock has to be taken, then memory allocated/deallocated, while other threads wait on the lock.
With tcmalloc, i would expect that the heap is broken up into parts so that each thread can use only its part of the heap and there is also a centralized heap where the thread will try to grab data from in case of running out of memory on its local heap.
(btw, just while on the topic, making a quick note about Valgrind's issues with tcmalloc: from valgrind man page: "When a shared library is loaded, Valgrind checks for functions in the library that must be replaced or wrapped. For example, Memcheck replaces all malloc related functions (malloc, free, calloc, ...) with its own versions. Such replacements are done by default only in shared libraries whose soname matches a predefined soname pattern (e.g.libc.so* on linux). By default, no replacement is done for a statically linked library or for alternative libraries such as tcmalloc. In some cases, the replacements allow --soname-synonyms to specify one additional synonym pattern, giving flexibility in the replacement".)
Tuesday, November 11, 2014
Saturday, October 18, 2014
Rate Control/Traffic Policing/Traffic Shaping
Again, nothing new and something quite well known in the networking literature (maybe networking 101 for some) but putting it out here just as a reference because i think this is used pretty commonly in the networking industry and folks should be aware about this.
Let's say the goal is to rate control events (an event can be anything like number of hits, or number of clicks or say number of bytes delivered etc.) so that incoming traffic can be handled without overwhelming one's servers. The most commonly used (in my experience) algorithm for rate control (shaping, policing) is the token-bucket or leaky bucket based on one's requirements. However, one may think about trying to use other algorithms e.g. a sliding window. Here are the pros and cons of each approach:
Let's say the goal is to rate control events (an event can be anything like number of hits, or number of clicks or say number of bytes delivered etc.) so that incoming traffic can be handled without overwhelming one's servers. The most commonly used (in my experience) algorithm for rate control (shaping, policing) is the token-bucket or leaky bucket based on one's requirements. However, one may think about trying to use other algorithms e.g. a sliding window. Here are the pros and cons of each approach:
- Sliding Window: In this approach, we specify the rate in the sliding window that we will accept .e.g B events in the window, and anything in excess will be dropped. This approach has the problem as shown below that it cannot handle burst properly. Especially in a pathological case, this algorithm has the risk of shaping the traffic incorrectly over a long duration. As one can see in the picture below, one reason burst could not be handled well was because our sliding window slid 1 slot at a time. If instead we slide a random amount, we have effectively constructed a "randomized algorithm", that would not be 100% accurate rate control but which will be on average expected to be pretty close to the expected rate. Further, one can combine the sliding window approach with the token bucket approach as outlined below.
.png)
- Leaky Bucket algorithm: In this algorithm, a "bucket" data structure is created, which can be implemented as a queue and packets are inserted into the queue when they arrive, and are taken out at a predefined fixed rate. If an egress event occurs and there is nothing in the queue, we say that an "underrun" has occurred. If there are too many packets in the queue, specified by a size of the queue, we say that an "overrun" has occurred. The question of how big a burst size can be is configurable and is called as the sustainable cell rate (or sustainable bitrate, or sustainable event rate). [Ref: Wikipedia, Image credits, Wikpedia]. This is useful as a jitter buffer i.e. a buffer to eliminate jitter i.e. packets/events come in at whatever rate , but they will go out at a fixed rate.

- Token Bucket algorithm: In this approach, tokens are generated at a constant rate (or whatever rate one wants), and then arriving events/data is queued up and then when a packet is supposed to be dequeued (See *). When the packet is dequeued, number of events associated with that packet are pulled out of the token bucket. [Image credits: this]. * Typically there is some logic for dequeuing, e.g. (A) when trying to dequeue media packets that have a timestamp .e.g. a PTS in a MPEG2 stream, the packets will sit in the queue till the system wall-clock time/timestamp reaches the PTS of the packet (B) Sometimes networking queues are implemented as simply list-driven e.g. reorder queue: one can keep a counter for the expected packet count, and keep egressing the packets that arrive in order. When a packet arrives out of order (greater than the one expected), the packets are queued up in a sorted queue. When the expected packet arrives, elements in the queue that are in order are dequeued (and passed to token check stage). Note that the token bucket algorithm can also run into problems with bursty traffic. One may need to have a token debt- algorithm to deal with certain scenarios (http://www.google.com/patents/US20110075562 where if the token count becomes negative, the egress is stalled till the count becomes positive again. This is good for shaping. What about Policing using token bucket ? That can be handled by having a lower bound for the debt. Our rate control/policer can only work in those bounds of debt. For policing, there could be a long-term debt checker, which if non-zero guarantees that our algorithm is token-non-negative, which means that the given stream is within bounds. If not, we drop.

- Hybrids: one can devise hybrids e.g. leaky bucket + token bucket, where the data incoming out of a leaky bucket comes at a fixed rate, and goes into the token bucket queue at that fixed rate and rate control and policing can be done at the outgoing packet level. For Policing, The Sliding window approach can also be combined with token bucket, where some number of tokens are generated every second, say B tokens/sec, so that way the burst shown in that example will go through, but had there been another burst (3rd), then that would be dropped. Thus, we would need to have negative debt tokens as described in the point 3 above.
Of course, when implementing these, one needs some kind of timer mechanism, and one can use the commonly used libevent to create timers using evtimer_new(), and evtimer_add() etc. Note that libevent's timing mechanism is heap based where insertions and deletions are O(lgn). (see minheap-internal.h)
One can of course, also implement timers using timing wheels: e.g. this http://25thandclement.com/~william/projects/timeout.c.html, where the insertions and deletions are O(1).
Thursday, August 14, 2014
spinlock vs mutex
found this info nice. noting it.
http://stackoverflow.com/questions/5869825/when-should-one-use-a-spinlock-instead-of-mutex
"In homogeneous multi-core environments, if the time spend on critical section is small than use Spinlock, because we can reduce the context switch time. (Single-core comparison is not important, because some systems implementation Spinlock in the middle of the switch"
is what i took away from it.
http://stackoverflow.com/questions/5869825/when-should-one-use-a-spinlock-instead-of-mutex
"In homogeneous multi-core environments, if the time spend on critical section is small than use Spinlock, because we can reduce the context switch time. (Single-core comparison is not important, because some systems implementation Spinlock in the middle of the switch"
is what i took away from it.
Monday, August 4, 2014
CBR over TCP
here is one study of trying to achieve a CBR over TCP:
http://www.cs.columbia.edu/~salman/publications/votcp-conext07.pdf
two scenarios:
(1) Let's assume that an encoder is generating X bytes/second - and this rate is constant at every time instant (howsoever small a time window we assume).
The goal is to send over these X bytes at Xbytes/second on the network. We would like to send X bytes/second using TCP, i.e. the instantaneous rate should be X bytes/sec.
We know that TCP's window is chosen to be min(receiver's flow control window, congestion control window (cwnd)), and if we want to have true CBR, we would like to send exactly same number of bytes per second till we experience a loss, and in case of loss somehow compensate for the multiplicative decrease by sending additional data . This is in my opinion pretty hard to achieve.
In other words, it is very hard for instantaneously constant CBR over TCP , however the average behavior over 1 second may be close to CBR.
http://www.cs.columbia.edu/~salman/publications/votcp-conext07.pdf
two scenarios:
(1) Let's assume that an encoder is generating X bytes/second - and this rate is constant at every time instant (howsoever small a time window we assume).
The goal is to send over these X bytes at Xbytes/second on the network. We would like to send X bytes/second using TCP, i.e. the instantaneous rate should be X bytes/sec.
We know that TCP's window is chosen to be min(receiver's flow control window, congestion control window (cwnd)), and if we want to have true CBR, we would like to send exactly same number of bytes per second till we experience a loss, and in case of loss somehow compensate for the multiplicative decrease by sending additional data . This is in my opinion pretty hard to achieve.
In other words, it is very hard for instantaneously constant CBR over TCP , however the average behavior over 1 second may be close to CBR.
Wednesday, June 25, 2014
Survey of algorithmic techniques
Follow up: Lots of interesting ideas for me
http://www.scottaaronson.com/blog/?p=458
I am going to sift through the literature and note down algorithmic techniques that one commonly finds and am going to make a map of problem<-->algorithm and its complexity.
Also here is a map of the whole of theoretical computer science. It is not of great relevance directly, but can be useful to know. Note also that recursive languages are the subset of recursively enumerable languages.
http://upload.wikimedia.org/wikipedia/en/6/64/Theoretical_computer_science.svg
http://www.scottaaronson.com/blog/?p=458
I am going to sift through the literature and note down algorithmic techniques that one commonly finds and am going to make a map of problem<-->algorithm and its complexity.
Also here is a map of the whole of theoretical computer science. It is not of great relevance directly, but can be useful to know. Note also that recursive languages are the subset of recursively enumerable languages.
http://upload.wikimedia.org/wikipedia/en/6/64/Theoretical_computer_science.svg
Tuesday, June 3, 2014
Friday, April 11, 2014
Thursday, April 10, 2014
Tuesday, March 11, 2014
Computer languages
There are broadly 2 categories of computer programming languages today viz.
- Imperative/Procedural Languages
- unstructured (gotos)
- structured (functions)
- modular (separatation of concerns)
- object oriented
- subject oriented (who calls the function in an object also matters (possible to be modeled in oo by using a parameter for subject))
- Declarative languages (describe what is to be done, rather than how)
- Constraint programming
- functional programming
- logic programming
- sql
- html etc
Wednesday, February 5, 2014
Tuesday, November 5, 2013
Lagrange multipliers
http://www.youtube.com/watch?v=ry9cgNx1QV8 liked this example.
I will describe very soon, why this is done the way it is.
I will describe very soon, why this is done the way it is.
Friday, November 1, 2013
Monday, September 30, 2013
Tuesday, September 24, 2013
Object Normalization
http://programmers.stackexchange.com/questions/84598/object-oriented-normalization
some popular design principles. Making a note for reference.
some popular design principles. Making a note for reference.
Tuesday, September 17, 2013

{kind=link}
{kind=link}
Monday, September 16, 2013
Generating Functions
These are useful because of Taylor and Maclaurin series (https://www.khanacademy.org/math/calculus/sequences_series_approx_calc/maclaurin_taylor/v/maclauren-and-taylor-series-intuition)
Just a handy tool to use (someday) (e..g http://en.wikipedia.org/wiki/Examples_of_generating_functions)
Just a handy tool to use (someday) (e..g http://en.wikipedia.org/wiki/Examples_of_generating_functions)
Monday, June 17, 2013
Proving that Greedy Algorithms is a Good choice
How to find out if an problem is amenable to the principle of optimality:
If we can find an algorithm to solve the problem, such that the optimal solution to the "sub-problem" can be found using the same algorithm, then we say that the the <Algorithm, Problem> tuple is amenable to the "principle of optimality".
for which principle of optimality applies, we can try to think through whether the problem necessarily needs a dynamic programming kind of a solution, or a greedy one will do.
Have a look at this as a template for proving that greedy algorithms are a good choice for a particular optimization problem, and this as an intro to the concept of knowing/finding out "when can greedy algorithms work i.e. for what structure of problems i.e. apparently (i will revisit this), "Most problems for which greedy approach works can be formulated in terms of Weighted Matriods"
If we can find an algorithm to solve the problem, such that the optimal solution to the "sub-problem" can be found using the same algorithm, then we say that the the <Algorithm, Problem> tuple is amenable to the "principle of optimality".
- e.g. lets say the Problem: Find the Shortest path for a graph with no negative edges (but with cycles) Let's choose Dijkstra's algorithm. We observe that if we run the same algorithm on any 2 points on this shortest path say path1, we will see that the newly found shortest path, say path2 is a subset of path1. Thus <Shortest path on a graph with no negative edges, Dijkstra> satisfies principle of optimality.
- <Longest path on a graph with no negative edges, Dijkstra> however is not amenable to the principle of optimality because e.g. imagine the longest path on a ring-like graph say made up of a-b-c-d-e-a . The longest path from a-d is a-b-c-d (and not a-e-d). And, the longest path from b-d is not b-c-d, but it is 'b-a-e-d'. This path cannot be found using Dijkstra. Therefore <Longest path on a graph with no negative edges, Dijkstra> does not satisfy principle of optimality. Of course <Longest path on a graph with no negative edges, some other algo A> may satisfy principle of optimality ! Is there any such algo? I do not know.
Have a look at this as a template for proving that greedy algorithms are a good choice for a particular optimization problem, and this as an intro to the concept of knowing/finding out "when can greedy algorithms work i.e. for what structure of problems i.e. apparently (i will revisit this), "Most problems for which greedy approach works can be formulated in terms of Weighted Matriods"
Wednesday, June 5, 2013
Homomorphic Encryption
A difficult (for me) topic, but i think this is an important piece of work. I will follow up on this area soon. I want to try to explain the basics from the paper.
http://crypto.stanford.edu/craig/craig-thesis.pdf
http://crypto.stanford.edu/craig/craig-thesis.pdf
Monday, April 15, 2013
Dummynet
Nothing new for the networking community i guess, but this is relatively new for me, so making a note. Sounds very interesting. http://info.iet.unipi.it/~luigi/dummynet/
Will update soon.
Will update soon.
Thursday, April 4, 2013
Polynomials and Galois Field extensions
Let's say the goal is to find out if an error occurred during transmission, and if it did, correct it. Let us look at our codes
A quick and to-the-point intro to algebra of polynomials and the extensions of its coefficients from GF(2) to GF(2^k), based on what is defined as an irreducible polynomial in GF(2), (and we look for irredicible polynomials that are also "primitive polynomials" and construct a GF(2^k) using a symbol that would be the root of this primitive polynomial etc.)
http://www.uotechnology.edu.iq/dep-eee/lectures/4th/communication/information%20theory/8.pdf

The point is, with GF(2), 0 and 1 symbols are interpreted as the values that the polynomial's variables can take, but with GF(2^k), k bits become the symbols and based on properties of the GF(2^k) certain error correction can be done. An example is a BCH code where the input symbols are first multiplied by the degree of the generator polynomial (of the field), (See this, page 13-14 for an example). I will revisit this soon.
- If the code is a binary code, i.e. the symbols are 0 and 1, then a 0 may in error come as 1 and 1 as 0. How will the decoder know ? It cannot ! there is no way to know
- If instead we say that the symbols are from 2^2 i.e. 2 bits, then we can say that we have only 2 symbols (00 and 11) if we get a 01 or 10, we say that we have "detected an error"
- Further, if we wan't to transmit say codes that are say 8 bits (2^3 e.g. ascii), how should we transmit it ? It turns out that if we wan't to add, subtract, divide, multiply elements together, we are essentially talking about a mathematical structure called a field. Why do we want to add, subtract, multiply, divide elements together ? The hope is that we can find some clever way to detect or correct errors. Let us investigate where this field related stuff can take us
- One issue with a Finite field is that it can be constructed only with elements that are a power of $$p^m$$, where $$p$$ is a prime. (See this). Therefore one thing to try is to look at a field with $$Z_{2^m}$$ elements and see what addition, multiplication, etc leads us to. We need to find the $$m$$ here of course.
- The trouble it turns out is that elements in $$Z_{2^m}$$ do not all have inverses, so instead we move to polynomial arithmetic (See this for more clarification. I will also touch this again soon)
A quick and to-the-point intro to algebra of polynomials and the extensions of its coefficients from GF(2) to GF(2^k), based on what is defined as an irreducible polynomial in GF(2), (and we look for irredicible polynomials that are also "primitive polynomials" and construct a GF(2^k) using a symbol that would be the root of this primitive polynomial etc.)
http://www.uotechnology.edu.iq/dep-eee/lectures/4th/communication/information%20theory/8.pdf

The point is, with GF(2), 0 and 1 symbols are interpreted as the values that the polynomial's variables can take, but with GF(2^k), k bits become the symbols and based on properties of the GF(2^k) certain error correction can be done. An example is a BCH code where the input symbols are first multiplied by the degree of the generator polynomial (of the field), (See this, page 13-14 for an example). I will revisit this soon.
Monday, April 1, 2013
Wednesday, February 27, 2013
Secure Boot
Making a list of "Secure boot" related issues i came across.
- definition of secure boot: http://www.intel.com/support/motherboards/desktop/sb/CS-033869.htm
- How linux handles :http://www.linuxfoundation.org/news-media/blogs/browse/2012/10/linux-foundation-uefi-secure-boot-system-open-source
- Signed Kernel Modules :http://www.linuxjournal.com/article/7130
- Stackoverflow question about how to sign kernel modules: http://stackoverflow.com/questions/3879595/kernel-mode-code-signing
Monday, January 21, 2013
PAXOS
Best URL i came across to understand PAXOS:https://distributedthoughts.com/2013/09/22/understanding-paxos-part-1/

https://distributedthoughts.com/2013/09/30/understanding-paxos-part-2/

Tuesday, January 8, 2013
Density Property
A quick reminder of the density property of rational numbers: http://mathforum.org/library/drmath/view/56025.html
Sunday, January 6, 2013
Webpage Analysis tools
Making a list of tools and insights that have helped/are helping me understand the web better.
Thursday, December 6, 2012
Monday, November 12, 2012
Post Vs Put
According to RFC 2616
The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line. […] The actual function performed by the POST method is determined by the server and is usually dependent on the Request-URI. The posted entity is subordinate to that URI in the same way that a file is subordinate to a directory containing it, a news article is subordinate to a newsgroup to which it is posted, or a record is subordinate to a database.
PUT is defined as:
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI.
See this for a discussion. What eventually i am going with is this understanding:
This is specified in RFC 2616 §9.5ff.POST creates a child resource, so POST to/itemscreates a resources that lives under the/itemsresource. Eg./items/1PUT is for creating or updating something with a known URL.
Therefore PUT is only a candidate for CREATE where you already know the url before the resource is created. Eg./blogs/nigel/entry/when_to_use_post_vs_putas the title is used as the resource key
Tuesday, October 30, 2012
API vs SDK
http://stackoverflow.com/questions/834763/api-vs-sdk
API could be said to be the "declaration" and the SDK the "declaration + implementation(definition)" of an interface(method/technique to drive/use something)
Note that in OOP, the interface is usually a virtual class (C++), or an interface (Java). People can do 2 things with such a class/interface.
API could be said to be the "declaration" and the SDK the "declaration + implementation(definition)" of an interface(method/technique to drive/use something)
Note that in OOP, the interface is usually a virtual class (C++), or an interface (Java). People can do 2 things with such a class/interface.
- If what the programmer is provided is just an API with no accompanying implementations - he/she can implement the interface aka create a derived class and use the base class' pointer to call the functions defined.
- If what the programmer is provided is an SDK, with the interface specified in a virtual class (or an "interface") then the libraries provided will implement the SDK... all the programmer needs to do is to instantiate the object of this interface (as specified in the documentation), and then use it.
Wednesday, October 10, 2012
Gates with dominos
Came across this interesting post : http://mathlesstraveled.com/2012/10/10/making-a-computer-out-of-dominoes/
and this link explaining the AND gate using dominos.
and this link explaining the AND gate using dominos.
Tuesday, October 9, 2012
Functors/ Function Objects
http://www.experts-exchange.com/articles/849/Function-pointers-vs-Functors.html is the way to handle function pointers in C++ so that the passing function pointer is override-friendly (no casting needed), and the function can maintain state of the object it is in, what one needs is a functor.
http://stackoverflow.com/questions/356950/c-functors-and-their-uses .
Functor is a function which retains state.
http://stackoverflow.com/questions/317450/why-override-operator?lq=1
http://stackoverflow.com/questions/356950/c-functors-and-their-uses .
Functor is a function which retains state.
http://stackoverflow.com/questions/317450/why-override-operator?lq=1
Saturday, September 8, 2012
Quick List of *HOT* software technologies
Listing some software technologies that are *hot* these days. I have touched upon them in the past in some senses. Just bringing it all together.
Web frameworks for Web services: Goal is to pushing pages and delighting users[1]
Web frameworks for Web services: Goal is to pushing pages and delighting users[1]
- Node.js: Event driven server side javascript based "server", to deal with sysadmin capabilities and low level routing [1]
- Ruby on Rails: A web framework based on the Ruby Language
- Ajax: Method to render only small sections of the page as necessary from the user/client perspective by talking to the server side framework. (Some Ajax frameworks are even embedded as a part of larger frameworks. For example, the jQuery JavaScript Library is included in Ruby on Rails.[Wikipedia])
Clouds & Virtualization Infrastructure:
- Amazon's EC2 cloud: A web service interface that allows one to obtain and configure capacity in the cloud managed by Amazon, where new server instances can be boot up in minutes allowing to quickly scale capacity, both up and down, as your computing requirements change. Amazon EC2 changes the economics of computing by allowing you to pay only for capacity that you actually use. Amazon EC2 provides developers the tools to build failure resilient applications and isolate themselves from common failure scenarios. Here is the marketplace for the applications written based on the EC2 cloud. Here is a link to AWS developer community resources. This internally leverages virtualization technologies and Big-data technologies.
- See this Virtualization Journal for advances
Big Data: Technologies to solve problems in distributed systems and to deal with large data.
- Apache Hadoop Project: Java based technology that helps to leverage multiple commodity hardware to deal with big data (however typically for performance, this "commodity hardware" is really high end machines). Hadoop is an java-based open source implementation of the Google MapReduce model (which in turn bears similarities with the MPI Map-Reduce model). Google is thought to implement the map-reduce in C++.
OpenFlow and SDN:
- Openflow is a layer-2 protocol to talk to a switch or router so as to get access to the switch or router's forwarding plane and tell the switch to take certain decisions. Openflow is considered to be an enabler of SDN (of course one can always do SDN by SNMP or by CLI. See a past blog)
Android and Apple App development:
Sunday, September 2, 2012
Copy Constructor
http://www.velocityreviews.com/forums/t283016-question-on-copy-constructor.html as to why the argument of the copy constructor needs to be pass-by-reference
(note that there are 2 ways of passing arguments in C++, one is by value (copy constructor is involved), and one is by reference)
See Wikipedia for examples
(note that there are 2 ways of passing arguments in C++, one is by value (copy constructor is involved), and one is by reference)
See Wikipedia for examples
Saturday, September 1, 2012
Depth from Monocular images
http://ai.stanford.edu/~asaxena/learningdepth/NIPS_LearningDepth.pdf
and as one finds in the paper, a pointer to http://en.wikipedia.org/wiki/Markov_random_field
and as one finds in the paper, a pointer to http://en.wikipedia.org/wiki/Markov_random_field
Monday, August 27, 2012
Video Scrambling method
http://www.cl.cam.ac.uk/~mgk25/nagra.pdf had a nice view into how scrambling could be done (and in turn could be broken). Was good for my own info, so putting it up.
Monday, August 20, 2012
Facebook Database design
http://stackoverflow.com/questions/1009025/facebook-database-design, but of course it may be NoSQL based. (follow up)
Sunday, August 19, 2012
Exception Handling implementation
http://en.wikipedia.org/wiki/Exception_handling#Exception_handling_implementation Intro to how languages implement exception handling.
Thursday, August 16, 2012
Friday, August 10, 2012
Linux Timers
http://www.ibm.com/developerworks/linux/library/l-timers-list/ as to how timer-related-callbacks are implemented in Linux. This is something i have used in the past, though came across this page, so making a note for reference.
Tuesday, August 7, 2012
Saturday, August 4, 2012
Friday, August 3, 2012
Design patterns
I have wondered for a while, why people keep talking about design patterns, and looks like i should have studied this long time back - reason - because if nothing else they are an effective benchmark to differentiate one language from another.
Have a look at this article by Paul Graham about how 2 different 1950 paradigms
Have a look at this article by Paul Graham about how 2 different 1950 paradigms
- Lisp
- Fortran
Also, of course, i do not know all the patterns listed here, but learning them http://en.wikipedia.org/wiki/Software_design_pattern#Classification_and_list. I suspect i have used some of these patterns without knowing their names, though good to know them formally.
Broadly speaking there are 3 types of design patterns [ ref: this ]
Broadly speaking there are 3 types of design patterns [ ref: this ]
- Structural: patterns generally deal with relationships between entities, making it easier for these entities to work together. e.g. a Decorator which will add some tags to the URL based on context.
- Creational: patterns provide instantiation mechanisms, making it easier to create objects in a way that suits the situation.e.g. Factory, similar to an adaptor/wrapper for "creating" different types of objects. Another example is the Singleton design pattern: here is a quick link for the difference between a singleton pattern and a static class (note that a static class is a concept that is in C#, not in C++). Singleton's lead to objects that can be passed as arguments etc
- Behavioral : patterns are used in communications between entities and make it easier and more flexible for these entities to communicate e.g. Strategy pattern, adapter/wrapper
Wednesday, August 1, 2012
Suffix Tree and String matching
Just found out that there is a popular data structure to deal with substring kind of problems, called the "Suffix Tree". (constrast with "Prefix tree", which is used in longest prefix kind of problems)
Suffix tree can be constructed with the simple O($$n^2$$) algo (insert the "n" suffixes of a string with n chars into the tree creating a child wherever necessary) or with more advanced algorithms that can do it in O(n) (http://en.wikipedia.org/wiki/Ukkonen%27s_algorithm). The point is, once we have a suffix tree, we can execute several of these algorithms in linear time.
Ref: http://www.csc.liv.ac.uk/~leszek/COMP526/week5/week5.pdf
Suffix tree can be constructed with the simple O($$n^2$$) algo (insert the "n" suffixes of a string with n chars into the tree creating a child wherever necessary) or with more advanced algorithms that can do it in O(n) (http://en.wikipedia.org/wiki/Ukkonen%27s_algorithm). The point is, once we have a suffix tree, we can execute several of these algorithms in linear time.
- Longest repeating substring: the node which is farthest away from the tree but which has degree > 1.
- Longest substring which is also a palindrome: to do this, we take te original string lets say abcac and concatenate it with itself reversed i.e. abcaccacba and run "longest repeating substring"
- Longest common substring: where we concatenate 2 strings first e.g. abcd and bcd so as to get abcdbcd and now search for the node deepest down which has degree > 1.
- Shortest substring that occurs only once: to answer this, we find the node with the shortest length that takes us to a leaf node.
Ref: http://www.csc.liv.ac.uk/~leszek/COMP526/week5/week5.pdf
Monday, July 30, 2012
Web Frameworks
http://en.wikipedia.org/wiki/Comparison_of_web_application_frameworks
Further, have a look at these graphs for the usage of a variety of lightweight web frameworks out there.
Java based web frameworks:
I have some experience with a 'heavyweight J2EE' application and was thus interested in knowing the lightweight web frameworks out there. (http://docs.jboss.com/books/lightweight/ch01.html). Also found this http://www.it.uom.gr/teaching/applicationsIT_1/lectures/ which was useful as a intro to Java based web frameworks. Also look at http://www.it.uom.gr/teaching/applicationsIT_2/
Further, have a look at these graphs for the usage of a variety of lightweight web frameworks out there.
Java based web frameworks:
I have some experience with a 'heavyweight J2EE' application and was thus interested in knowing the lightweight web frameworks out there. (http://docs.jboss.com/books/lightweight/ch01.html). Also found this http://www.it.uom.gr/teaching/applicationsIT_1/lectures/ which was useful as a intro to Java based web frameworks. Also look at http://www.it.uom.gr/teaching/applicationsIT_2/
Saturday, July 28, 2012
Query Rewriting using Views
Have a look at this thesis to get an idea as to how a SQL query can be rewritten given that some views (named queries) of the database are already available.
Friday, July 27, 2012
Simpson's Paradox
Have a look at this paradox called Simpson's paradox. Again, one of those things, which are pretty obvious/straightforward/easily-deduced based on evidence, but seems counter-intuitive. The vector diagrams suggest why it works and why we dont catch the problem. (See how the second blue vector is "long" even though it has less rate than the second red vector)
Monday, July 16, 2012
Big Data and Relational Databases
http://dba.stackexchange.com/questions/13931/why-cant-relational-databases-meet-the-scales-of-big-data
Note the discussion about the way the data is structured (whether it facilitates partitioning e.g. )
Note the discussion about the way the data is structured (whether it facilitates partitioning e.g. )
Tuesday, June 26, 2012
Router Virtualization
Was trying to find out how one can virtualize the cisco router in ESX.
Have a look at this for some motivation behind this.
The following methods are possible today:
Have a look at this for some motivation behind this.
The following methods are possible today:
- Create a virtual Linux box and run Quagga or XORP on it.
- http://www.thevarguy.com/2012/07/23/vmware-nicira-vs-cisco-insieme-virtualized-network-war/
- Can Openflow be of relevance [see this], and this
Tuesday, May 22, 2012
Clustering complexity
Here is a paper, which says "Clustering is difficult, only where it does not matter".
Thursday, May 17, 2012
Friday, May 11, 2012
Some Basic PHP Internals
http://stackoverflow.com/questions/971279/how-the-sausage-is-made-tour-of-apache-php-mysql-interaction
The above link led me to this, and from there info about the Zend Engine and PHP request life cycle.
The above link led me to this, and from there info about the Zend Engine and PHP request life cycle.
Tuesday, April 24, 2012
Replication in distributed systems
http://en.wikipedia.org/wiki/Replication_(computing)
Note the advantages and disadvantages of synchronous and asynchronous replication methods
Note the advantages and disadvantages of synchronous and asynchronous replication methods
Monday, April 23, 2012
Payoffs for Mixed Strategies
https://www2.bc.edu/~sonmezt/E308SL7.pdf
Further, one could apply the ideas presented in the above pdf, to a one-shot simultaneous game. (i.e. a simultaneous game played only once)
Assume a 2-person game where the goal of the game is to win.
Also, of course that real life interactions are very rarely one-shot i.e. most are repeat-games, and that is why many other factors start coming into the picture. (including ethics and what not). As an example have a look at this which suggests how and why social-diversity may in fact lead to cooperation and altruism.
Further, one could apply the ideas presented in the above pdf, to a one-shot simultaneous game. (i.e. a simultaneous game played only once)
Assume a 2-person game where the goal of the game is to win.
- Lets assume a one-shot game. In this situation, what if the Payoff Matrix has no obvious Nash Equilibria i.e. at least 1 player finds that its best to change the decision. What is the best strategy in this situation. One way to think is as follows
- Assume that the game is a repeated game. Now if one does not want to be exploited, the strategy is to mix up one's decisions. How should this mixing be done ? In order to minimize the payoffs of the other person, it is best to seek the minimum of the maximum payoffs the other player -- why so ? (have a look at the article), and in doing so one finds the mixed strategy.
- Once one knows the mixed strategy, choose the decision with the highest yeild in the long-run as the decision for the one-shot game.
Also, of course that real life interactions are very rarely one-shot i.e. most are repeat-games, and that is why many other factors start coming into the picture. (including ethics and what not). As an example have a look at this which suggests how and why social-diversity may in fact lead to cooperation and altruism.
Stack Machines vs. Register Machines & more
http://www.codeproject.com/Articles/461052/Stack-based-vs-Register-based-Virtual-Machine-Arch
Java VMs are stack-machines, here is one link
and the Android Davlik VM is based on a register-based-architecture.
and also
This is of course not a big deal, i.e. stack machines are just a way of compact code, but under the hood it of course uses registers to execute the code.
Java VMs are stack-machines, here is one link
and the Android Davlik VM is based on a register-based-architecture.
"The stack machine style is in contrast to register file machines which hold temporary values in a small fast visible array of similar registers, or accumulator machines which have only one visible general-purpose temp register, or memory-to-memory machines which have no visible temp registers."Here is a comparison (USENIX) of stack vs register machines. To quote from the paper:
"For example, the local variable assignment a = b + c might be translated to stack JVM code as ILOAD c, ILOAD b, IADD, ISTORE a. In a virtual register machine, the same code would be a single instruction IADD a, b, c. Thus, virtual register machines have the potential to significantly reduce the number of instruction dispatches."
and also
"In the stack-based JVM, a local variable is accessed using an index, and the operand stack is accessed via the stack pointer. In the register-based JVM both the local variables and operand stack can be considered as virtual registers for the method. There is a simple mapping from stack locations to register numbers, because the height and contents of the JVM operand stack are known at any point in a program"Here is a comparison (Wikipedia) of different Application Virtual Machines
This is of course not a big deal, i.e. stack machines are just a way of compact code, but under the hood it of course uses registers to execute the code.
Wednesday, April 18, 2012
ARPs and VLANs
Quick note: https://learningnetwork.cisco.com/message/88223
Also, note how inter-VLAN routing is set up : http://www.cisco.com/en/US/docs/switches/lan/catalyst5000/hybrid/routing.html#wp29604
VLAN Hopping:
Making this as a security note.
Also, a quick recap of LAN vs. MAN vs. WAN protocols. Note specifically the different protocols that are used by each kind of network.
Also, note how inter-VLAN routing is set up : http://www.cisco.com/en/US/docs/switches/lan/catalyst5000/hybrid/routing.html#wp29604
VLAN Hopping:
Making this as a security note.
Also, a quick recap of LAN vs. MAN vs. WAN protocols. Note specifically the different protocols that are used by each kind of network.
Monday, April 16, 2012
Image Processing in Matlab
Found a couple of links on the Mathworks page related to a few (perhaps basic) aspects of image processing.
- http://www.mathworks.com/help/toolbox/images/f20-9579.html Link to ideas (with examples) such as image registration, filtering, ROI enhancement, morphological enhancements. etc.
- http://www.mathworks.com/help/toolbox/images/f8-20792.html Link to some examples about Color space. I will soon upload a pictorial form of how colors are represented by different types of color spaces. One common type of color space is RGB color space, which one can image as a sphere with 3 "corners" jutting out. The color space of a device is a subset of this color space. There are different ways of looking at it e.g. RGB, Hue/Sat/Value, YUV (e.g. using the Jab notation e.g. 4:2:0, :4:1:1 etc), etc.
Sunday, April 15, 2012
Linux Networking Stack Performance
Here is a link about the TCP/IP stack on Linux 2.4 and 2.6. The key insights are as follows
- Kernel Locking improvements: For SMP, Linux 2.6 still does use the "Big Kernel Lock" to prevent different CPUs from accessing the kernel at the same time , but it has finer granularity.
- Efficient copy routines in 2.6
- 2.6 Kernel uses the O(1) scheduler, and post 2.6.23 uses a O(log n) scheduler . See this and this and this (Info about how sessions are made up of processes and how tty is associated with the session, processes/tasks are made up of threads that share the thread group id, the O(1) algo using 2 runqueues per CPU, task priority, nice values etc.)
Thursday, April 12, 2012
St. Petersburg Paradox
http://en.wikipedia.org/wiki/St._Petersburg_paradox is a 'paradox' where a player pays some fixed amount (say $20) to enter the game, and it appears that the expected gain from the game is infinite dollars. Therefore, the debate is that the player should pay infinite dollars for the entrance (not $20). The counter argument is that the player argues that i've paid $20, but the heads could show up at the first coin flip itself and so i will be left with a loss. Further, even though i may get a lot of money later the probability of that happening is extremely low -- this diminishing probabilities of riches seems to put off most people - yet - mathematically, the "expected" returns are infinite. This is thus argued to be a case for the rejection of mathematical expectation i.e. our psychology goes against the mathematical (long term and statistical certainty) because in real-life we cannot play infinitely long and we do not have infinite (or large) amounts to bet.
Btw, as a tangential (not at all related to betting and expectations but a side-point about the usage of the word 'average') and a somewhat funny point (though unrelated to the expectation issue), is that one can have a population where almost EVERYONE is above average. e.g. if there are just a few people with 1 leg, 1.99 could be the average number of legs in the population which is <2 for almost everyone. Of course this is kind of obvious that we aren't talking about the median, but ive often seen these two things being confused.
Btw, as a tangential (not at all related to betting and expectations but a side-point about the usage of the word 'average') and a somewhat funny point (though unrelated to the expectation issue), is that one can have a population where almost EVERYONE is above average. e.g. if there are just a few people with 1 leg, 1.99 could be the average number of legs in the population which is <2 for almost everyone. Of course this is kind of obvious that we aren't talking about the median, but ive often seen these two things being confused.
Book on Algorithms in Computational Geometry
Book on Algorithms in Computational Geometry e.g. convex hulls, line intersections, triangulations, point location/trapezoidal maps, Voronoi Diagrams etc.
To be honest, this was amongst the more beautiful things i have seen of late
One example of the utility of this is GPSes, which as i understand will use methods to find out "intersections" of layers of roads etc, followed by some kind of routing algorithms (Dijkstra?).
If a region/node has a weight, instead of an edge having a weight and if we want to minimize the weight, one way to do that is to from one node, construct edges to "neighboring" nodes with a weight of the destination node and then use Dijkstra?(confirm)
To be honest, this was amongst the more beautiful things i have seen of late
One example of the utility of this is GPSes, which as i understand will use methods to find out "intersections" of layers of roads etc, followed by some kind of routing algorithms (Dijkstra?).
If a region/node has a weight, instead of an edge having a weight and if we want to minimize the weight, one way to do that is to from one node, construct edges to "neighboring" nodes with a weight of the destination node and then use Dijkstra?(confirm)
Sunday, April 8, 2012
Some machine Learning info
I am going to list things i came across while my feeble attempts at learning machine-learning.
Classification:
E.g. To do document classification we perform at least some of the following tasks.
Classification:
E.g. To do document classification we perform at least some of the following tasks.
- Get some training data, clean and stem the text.
- Represent your documents as vectors
- Perform feature selection
- Select your classifier and train it,
- Run the classification on some test data to see how well it performs
Thursday, April 5, 2012
Some DHCP/IPTables/Squid Fun
This is one example of using IP tables (Wikipedia, Tutorial) on the router to redirect packets to a gateway/proxy (such as Squid), when connected to the wireless on the airport/home etc. The interesting thing (for me) about the post, was the use of DHCP ranges so as to give a different experience of the internet to a certain section of people. Useful to note for future i thought.
A note on IpTables from here:
iptables is built on top of netfilter, the packet alteration framework for Linux 2.4.x and 2.6.x. It is a major rewrite of its predecessor ipchains, and is used to control packet filtering, Network Address Translation (masquerading, portforwarding, transparent proxying), and special effects such as packet mangling.
A note on IpTables from here:
iptables is built on top of netfilter, the packet alteration framework for Linux 2.4.x and 2.6.x. It is a major rewrite of its predecessor ipchains, and is used to control packet filtering, Network Address Translation (masquerading, portforwarding, transparent proxying), and special effects such as packet mangling.
Advances in Video Coding
A list of recent advances in video coding
- Distributed Coding : Wyner-Ziv coding where source statistics are exploited at the decoder allowing relatively lighter encoding phases. H.264 is used as an intraframe encoder and Wyner-Ziv frames are inserted in between intra-frames, where after integer transform of the frame, followed by LDPC coding of the transformed-data after which only parity bits are sent
- Texture based methods
- Scalable coding: Temporal, Spatial, SNR: e.g. code "enhancement" layers as B frames with a hierarchical structure
- Multi-view coding
- ROI based coding: Region of interest. See this
- Conditional Replenishment : See this
Ref[1]
Further, there are advances known for video streaming such as
- Adaptive bitrate coding: Encode the video with multiple bitrates and chunk it.
- Byte streams (instead of bitstreams)
- Reduce Pre-roll time
- Multi-source video streaming over WLANS. ref[2]
Wednesday, April 4, 2012
Book on Cognitive Science
http://www.goertzel.org/books/complex/contents.html
Liked what ive read so far in the book about Cognitive Science, AI, Dynamical Systems overview etc.
Liked what ive read so far in the book about Cognitive Science, AI, Dynamical Systems overview etc.
Thursday, March 29, 2012
Wednesday, March 28, 2012
Affinity Lattice
lets say there are 3 bits 000, the graph im interested in looks like this
111 ------\
/ \ \
011 101 |
/ \ / \ |
| 001 | |
| | | |
| 000 | |
\ / \ / |
010 100 |
\ / /
110 ------/
note that this is the graph where we go from one node to another if 1 bit changes. What i have drawn above is essentially a cube flattened out. The trouble is that i cannot draw a planar/non-overlapping graph/lattice for 4 dimensional codes.I am curious to find out if it is even possible at all to draw a hypercube on paper without overlapping edges.
Further, we cannot write this in a row-by-row table because the geometry of the table does not allow more than 2 neighbors.
What i am essentially looking for are geometric objects into which these codes can be embedded, and i want to call those geometric objects as "Affinity Objects" perhaps Affinity lattices.
Let me get back on this and find out the literature about this
Monday, March 26, 2012
Intro to File Systems
Quick high-level intro to File Systems on Linux. File System design can be motivated by things such as trying to reduce the seek-time (thereby latency, thereby increase throughput) and reduce the wait-time for write operations, and to achieve ACID (or not).
- Berkeley Fast File System: Place "sibling" files in nearby blocks. Boot blocks + superblock + cylinder groups (free-list + inodes(permissions, first 10 data blocks + indirect blocks) + directory blocks + data blocks). The MS-DOS FAT is a simpler version of this.
- Journaling File Systems:
- Metadata Journaling file systems: Maintain a log/Journal of the meta-operations related to allocating inodes, dirs, blocks, but dont actually store the data being written to blocks, into the log/Journal. [2] e.g. EXT3FS
- Log Structured File System[1] [2]: See this for a quick high level understanding. To avoid circular logs and fragmentation, "segments"/pools of free segments etc are used based on Garbage Collection techniques. [Wikipedia]
- Hierarchical File Systems: [Wikipedia]
- Distributed File Systems [Wikipidia]
- Chunked file systems e.g. Google File System
Have a look at this Wikipedia page :http://en.wikipedia.org/wiki/Comparison_of_file_systems
Wednesday, March 14, 2012
Internet Next-Gen
Some Proposals:
- Today there is quite a bit of data on the internet that is public. This has in fact been the reason why Google could crawl so much of data. The issue is that when content is going to get locked up into social networks, internet quickly approches the society of humans i.e. privacy/information sharing/hiding etc for political agendas may follow. What is needed here is some governing mechanism to allow sites to interoperate and share data for searches. Some data like Wikipedia is in the best-interests of everyone to be shared. There needs to be thinking about how data is going to be shared across social networking silos.
- Named Data Networking: Routers cache index to data. Effort made by routers is to find the path to the router that has access to content, rather than to attempt to connect to some end point, and treats content as the entity of primary importance, than treating destination IP as the entity of primary importance. Data can re thus retrieved based on the URL(i.e. URL without the host)
Monday, March 12, 2012
Sunday, March 11, 2012
On Caches
This is quite a vast topic, because so much of what the work that is done in the Computer Science field is an extension of some-sort-of-cacheing by some entities. One can in fact look upon a major chunk of the computer science field itself as a search for "better" cacheing techniques. (the meaning of "better" changes with applications)
The simplest way of cacheing is of course, store data in a hash table with the key as the "address" and the value as the data. This kind of cacheing is called an associative array or hash based cacheing.
However, we can generalize this process a bit by trying to map the entire address space into a smaller address space. I will start off the discussion with the caches as one finds in Computer Organization books i.e. caching of data one finds in slower memories into faster memories. In such types of cacheing, there are 4 things of interest and we can arrange the 4 things (line-number, set, tag, and element-offset; to be discussed soon) in 4! or 24 ways, so there are at least 24 types of caching possible. I am saying at least 24 because one may use advanced data structures to implement caches which will scale up the total types of caches possible.
Organization:
See figures for an conceptual understanding. Caches are in reality not necessarily flat as shown here. The flat caches as ive drawn is perhaps the simplest way to explain it. I will briefly discuss 2 alternative ways in which cacheing of data from CPU addresses can be achieved.
Type 1: Flat Cache/Tags are part of the Cache
See the following picture. Lets say the main memory is 2^A * k bytes. We can envision the memory address to be broken up into x, y, z as follows. The "address-chunk" is referred to as an "element" in literature.


Storage Benefits:
Cacheing benefits are achieved by the "tag field" being non-zero (e.g. shown as y > 0 bits). Note that we can potentially store the tag in a separate faster-memory than the cache, and this is often done (see this), but i am for now showing it part of the cache, as the tag is an important part/storage of the caching process.
Search:
The search process for caches is as follows:
The simplest way of cacheing is of course, store data in a hash table with the key as the "address" and the value as the data. This kind of cacheing is called an associative array or hash based cacheing.
However, we can generalize this process a bit by trying to map the entire address space into a smaller address space. I will start off the discussion with the caches as one finds in Computer Organization books i.e. caching of data one finds in slower memories into faster memories. In such types of cacheing, there are 4 things of interest and we can arrange the 4 things (line-number, set, tag, and element-offset; to be discussed soon) in 4! or 24 ways, so there are at least 24 types of caching possible. I am saying at least 24 because one may use advanced data structures to implement caches which will scale up the total types of caches possible.
Organization:
See figures for an conceptual understanding. Caches are in reality not necessarily flat as shown here. The flat caches as ive drawn is perhaps the simplest way to explain it. I will briefly discuss 2 alternative ways in which cacheing of data from CPU addresses can be achieved.
Type 1: Flat Cache/Tags are part of the Cache
See the following picture. Lets say the main memory is 2^A * k bytes. We can envision the memory address to be broken up into x, y, z as follows. The "address-chunk" is referred to as an "element" in literature.

Type 2: Flat Cache/Note the difference in the tag bits.

Storage Benefits:
Cacheing benefits are achieved by the "tag field" being non-zero (e.g. shown as y > 0 bits). Note that we can potentially store the tag in a separate faster-memory than the cache, and this is often done (see this), but i am for now showing it part of the cache, as the tag is an important part/storage of the caching process.
Search:
The search process for caches is as follows:
- Address --> find the cache line, or group of lines (if s > 0) associated with this address
- Search "associatively" within this set's tags and look for a match.
Question: What difference do these things (type 1 and type2) make ?
The answer is that in type1, "close" addresses map to the same line (the higher order bits in the address, decide the cache-line); and in type 2, "close" addresses map to different lines (as, relatively lower order bits in the address, decide the cache line)
As a result of this, type 2 is preferred, because cacheing wants to rely on principle of locality i.e. we want close addresses to map to different cache lines so that all those lines are in the cache when the processor needs them, effectively saving latency and increasing throughput.
Cache Eviction Logic:
In the above discussion the eviction logic was that, in case of "direct mapped cache" i.e. each line is a separate set, if the cache line one is interested in, is occupied with a different tag, we kick out that data and load new data.
If we are talking about a set-associative cache, then, we would potentially associatively search for a the tag match in all the lines in the "set", and then we have to decide some mechanism to kick out an entry - this may be done as LRU, LFU, FIFO etc (google for this).
Cache Coherency:
Distributed Caches & Partitioning: See this
Extensions:
Web Cacheing:
One can in principle extend this logic to cacheing in general, e.g. suppose we want to cache the content from www. google.com/blah1 and www.google.com/blah2. May it be nice to use higher-order bits (e.g. the www.google.com to map to a cache-block, or may be we better off using finer granularities (i.e. blah1, blah2) to store data. I would go with the latter for locality of reference. One can see that there is potential for research here too i.e. what is the performance benefits of each style depending on the browsing habits of the user.
Network Buffering:
Often, in networking systems, one may consider the caches to be made up of a pool of buffers separated in zones -- and thus in the above classification scheme, networking caches may be envisioned as; "zone" meaning a set, and buffers in a zone meaning the cache-lines in a set. The eviction scheme is used to figure out which buffer to re-use in a particular zone
Subscribe to:
Posts (Atom)